


-
09-06
-
06-10
-
12-29
-
07-12
-
12-29
如何打造数据驱动的知识型经济?这里有一份技术列表
发布时间:2020-12-31 13:16:39
文章来源:原创
访问次数:273

图片来源:摄图网
编者按:本文来自微信公众号机器之能(ID: almosthuman2017),作者机器之能,创业邦经授权转载。
过去的一年里,疫情让社会生活方方面面都受到了重挫,但也带来了一些有趣的副作用:倒逼企业数字化转型。
正如微软CEO萨蒂亚·纳德拉(Satya Nadella),「新冠疫情在数月内促进了企业的数字化转型。」
那些提前布局数字化的公司在疫情期间看到了收益,其他公司也在使用各种数字化工具,视频通话、远程办公、云计算、机器学习等得到了更多的应用。
但不管企业处于哪个阶段,随着数字化转型的加速,所有业务活动中越来越多的部分都在以数据的形式留下了足迹。每个员工、客户、供应商的动态,每个线索、信息位和过程都将以数字化的方式进行或记录。
反过来,这意味着从理论上讲,我们从数据中获得的应该不仅仅是对现状的洞察,还应该从数据到信息、从信息到知识。
在不久的将来,企业将是由数据驱动的,经济将是基于知识的。以下是知识型经济所需要的技术列表:
一 数据金字塔:从数据到知识
从1946年第一台计算机诞生,几十年IT技术的迅速发展下,人类从数据稀缺进入了数据爆炸时代,但我们一直没有解决的问题是,「如何将数据、信息转化为知识,扩大人类的理性,辅助决策?」
当前,我们对数据的利用还处在非常浅层的阶段,管理大师彼得·德鲁于上世纪90年代对数据使用的评论仍然适用于今天:「迄今为止,我们的系统产生的还仅仅是数据,而不是信息,更不是知识。」
数据、信息、知识,加上最高层级的智慧,四者之间的关系可以用「数据金字塔」来表示。这个金字塔一直以来都是信息科学语言的一部分,在基于知识的新数字世界中,对数据进行编码,利用商业、运营知识是取得进步和保持竞争力的关键。
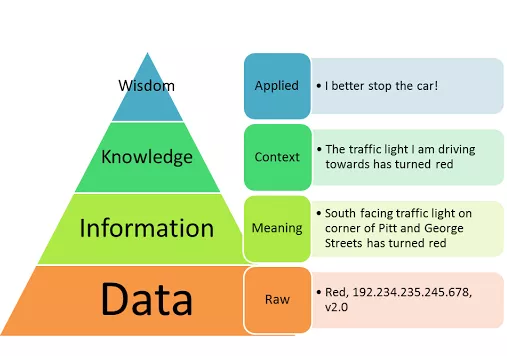
数据金字塔:数据、信息、知识和智慧之间的关系表示
那么,我们如何从数据到信息,从信息到知识呢?首先要解释三者的区别。
数据就是数字或字符,是原始或无组织形式的事实的集合,没有上下文,也没有意义。例如,「18122020」只是一个数字序列。但是,如果我们将此序列定义为DDMMYYY格式的日期,则可以将其解释为2020年12月18日。在此附加上下文中,数字具有含义。
信息是为了特定目的而以一种更容易测量、可视化和分析的方式处理的数据。例如,我们可以通过公开各种看似完全不同的数据点和断开连接的数据点之间的关系的方式来组织数据。根据每天休市时的数据创建特定时间段内数据点的图表来分析道琼斯指数的表现。
知识是经过某种方式处理、构造、应用或付诸实践的信息。例如,通过捕获和表达与我们的数据点相关的关系的含义,我们可以自动化地洞察,并提取新知识。语义关系的知识图谱可以帮助解释某些股票如何影响道琼斯指数,以及不同的事件如何影响它们的价格。
向数据添加上下文会将其转变为信息,处理信息可以将其转变为知识,这些转换的关键是「连接」和「元数据」。
提到数据处理,大部分人想到的是深度学习。如今通过深度学习,我们可以通过找到数据背后的规律,并作出预测。
但深度学习并不是唯一的数据处理方式,本篇文章尝试从一个不同的视角来分析,关注一个特定的数据结构:图。
二 图分析
图论的历史与一个看似完全毫无联系的问题有关,「通过柯尼斯堡(Königsberg)许多桥梁的最佳方式是什么?」1736年,瑞士数学家和物理学家莱昂哈德·欧拉(Leonhard Euler)建立了一个模型解决了这个问题,该模型就是图论的基础。
欧拉的做法是将「桥」和「连接桥的路径」建模为图中的「节点」和「边」,然后形式化节点和边的关系,这就构成了许多图形算法的基础。
在基于知识的新数字世界中,对数据进行编码和将数据与业务知识结合是取得进步并保持竞争力的关键。
最著名的图形算法可能是PageRank ——谷歌帝国的基础。PageRank将网络上的文档建模为图形,并使用它们之间的链接来得出特定查询的相关性。
从18世纪到今天,科学家们已经开发了许多图形算法,其主要类别包括路径查找、中心性、社区检测、相似性是图算法的主要类别,这些算法在数据分析中有很多应用。
从eBay到NASA,再到调查记者和独立数据科学家,图分析都有大量的应用,包括欺诈检测、网络分析、自然语言处理等。2019年,分析公司Gartner就预测过,「图分析将在未来几年内增长,因为人们需要在复杂的数据中提出复杂的问题。」
三 图数据库
前文提到,将数据转换成信息的关键是「连接」和「元数据」。图是利用连接的最佳方法,而图数据库则可以使表达和连接查询变得更容易。
这就是为什么图数据库非常适合那些需要利用数据连接(反欺诈、预测性建议)案例的原因。从操作应用到分析,从数据集成到机器学习,图都有优势。
但图和图数据库之间并不一样。图分析可以在任何后端执行,它们仅需要读取图形形状的数据。而图形数据库是一种能够完全支持读和写的数据库,利用了图形数据模型、API和查询语言。
图数据库其实已经存在很长时间了,但到2017年才收到广泛关注,当时AWS和微软分别使用Neptune和Cosmos DB将图数据库暴露给更广泛的受众。自那时以来,图数据库就成了数据管理中最热门的领域。
「到2022年,图形处理和图形DBMS的应用将以每年100%的速度增长,以不断加速数据准备并实现更复杂和适应性更强的数据科学。图形数据存储区可以跨数据孤岛有效地建模,探索和查询具有复杂相互关系的数据。」Gartner在《2019年十大数据和分析技术趋势》报告中表示。
四 知识图谱
连接数据孤岛是知识管理的前提,而知识图谱擅长于此。知识图谱是图的特定子类,也称为语义图。它们自带元数据、模式、全局标识符和推理能力,这使得它们成为捕捉和管理知识的理想选择。
很多人将知识图谱作为一项新技术,但实际上知识图谱已经存在了至少20年,其发明者正式万维网发明者蒂姆·伯纳斯·李(Tim Berners-Lee)。
2001年蒂姆·伯纳斯发表语义网宣言( Semantic Web manifesto),尽管其中提到的原则和技术一直有争议,但它仍然成为知识图谱复兴的幕后推手。
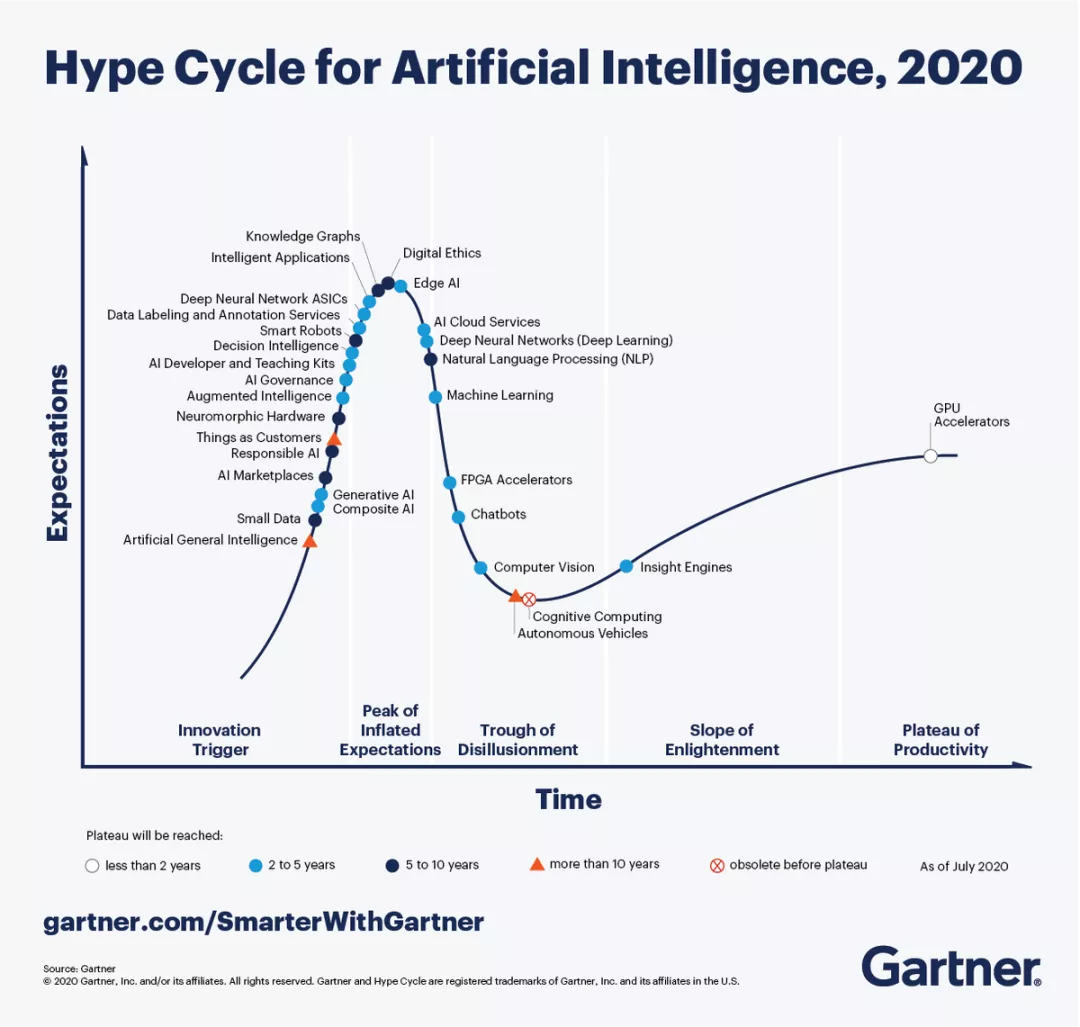
Gartner将知识图谱纳入2020年人工智能技术成熟度曲线报告,并将其作为处于高峰的新技术热点
谷歌的PageRank也在图及知识图谱的兴起中扮演重要角色。尽管PageRank取得了成功,但如果没有语义和元数据,网络上内容的抓取和分类同样是一个难解决的问题。因此,谷歌接受了语义技术,并在2012年创造了术语「知识图」。
schema.org的广泛采用标志着图技术和知识图谱迅速崛起的开始。知识图可以解决数据治理和数据集成等关键挑战。
最终,知识图谱可以作为数字载体,可以将知识获取和组织的理念与数字时代的数据管理实践统一起来。
五 图、AI和自然语言处理
如果你认为知识图谱是捕捉和管理知识的终极目标,那你就错了。知识图谱擅长以自上而下的方式明确地捕捉知识。这也是Gartner将知识图谱列入2020年人工智能成熟度曲线报告的原因。
在管理显性、先验知识方面,知识图谱比其他任何技术都要好,但是对于隐性、突发性及不断发展的知识而言,又如何处理?这就是机器学习效果很好的地方,但在这里,图形也可能会有所帮助。
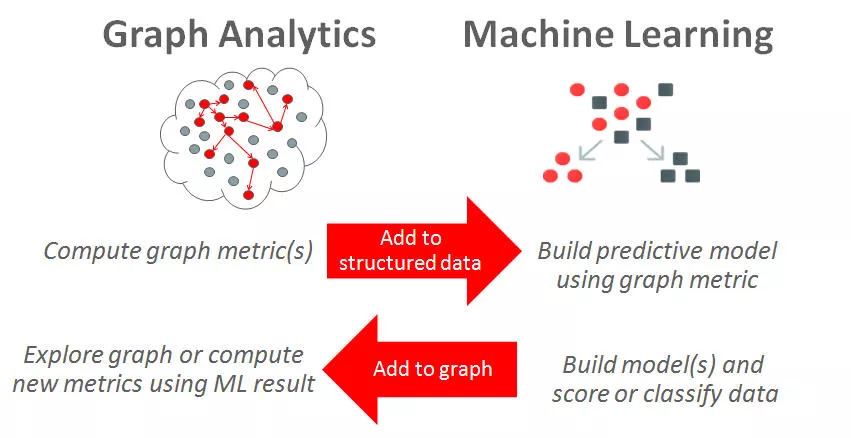
图与机器学习有什么关系?实际上很多。这是双向的。机器学习可以帮助引导和填充知识图谱。图形中包含的信息可以提升机器学习方法的效率。
机器学习及其深度学习子领域,与图形非常匹配。在图上的机器学习仍然是一项新兴的技术,但却是一项充满希望的技术。亚马逊、阿里巴巴、苹果、Facebook和Twitter只在一些生产中使用这项技术。在顶级人工智能会议上发表的研究报告中,有超过25%与图有关。
最后,根据Facebook人工智能研究员Fabio Petroni的说法,图可能不是获取知识的最佳方式。
本文链接:http://www.hzlm.nethttp://baibu123.com/internet/30.html
文章评论
共 0 条评论,查看全部
- 这篇文章还没有收到评论,赶紧来抢沙发吧~










最新资讯

 粤公网安备 34018102340473号
粤公网安备 34018102340473号 中国互联网举报中心
中国互联网举报中心